Azure AI Search can function as a vector database search when configured with vectorization and semantic search capabilities. Here’s how it works and where the vectors are stored:
✅ How Azure AI Search Works as a Vector DB
When you set up Azure AI Search to import and vectorize data (e.g., documents from a selected folder in a Blob Storage container), it performs the following:
Data Ingestion:
You define a data source (Blob Storage).
Azure Search pulls documents from the selected folder.
Vectorization:
You can use built-in vectorization (via Azure OpenAI embedding models) or bring your own embeddings.
Each document (or chunk of text) is converted into a vector representation.
Indexing:
These vectors are stored in a vector field within the Azure Search index.
You define this field in your index schema (e.g., contentVector).
Search:
You can perform vector similarity search using cosine similarity or other metrics.
Combine it with a keyword search for hybrid search scenarios.
📍 Where Are Vectors Stored?
The vectors are stored inside the Azure AI Search index itself. Specifically:
Each document in the index has a field (e.g., vector) that holds the vector embedding.
Azure Search indexes these vectors and uses them for similarity search.
You can configure the vector field with parameters like dimensions, vectorSearchAlgorithmConfiguration, etc.
🧠 Example Use Case
If you’re indexing PDFs or text files from Blob Storage:
Azure Search will chunk the documents.
Each chunk gets vectorized.
Vectors are stored in the index.
You can then query using a vector (e.g., from a user query) to retrieve semantically similar chunks.
✅ Outcome You now have a semantic index of your enterprise knowledge.
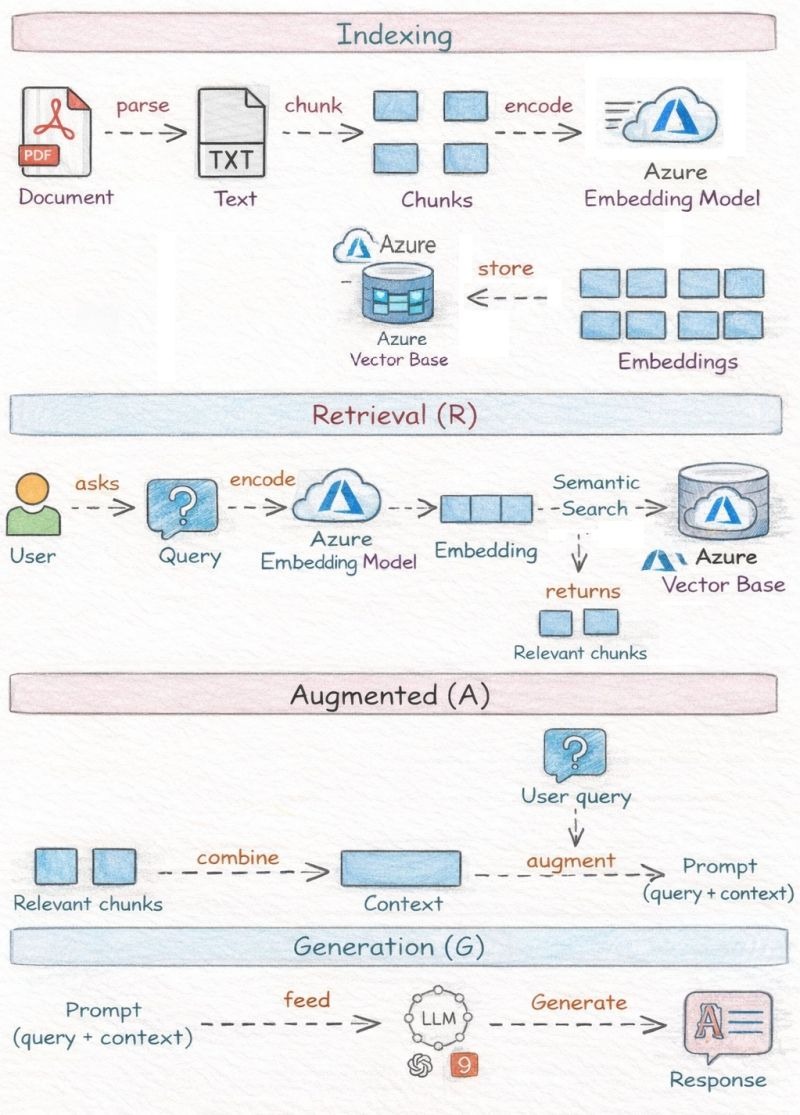
2️⃣ Retrieval Phase (R – Runtime)
This happens when a user asks a question.
Step 1: User query
User → “How does leave approval work?”
Raw natural language question.
Step 2: Query embedding
Query → Azure Embedding Model → Query Vector
The same embedding model used during indexing must be used here
This ensures vector space consistency
✅ Important Using different embedding models breaks similarity search.
Step 3: Semantic search in vector DB
Query Vector → Similarity Search → Top‑K chunks
Cosine similarity / dot product used
Returns most semantically relevant chunks
✅ Often combined with:
Metadata filters (department, date, access level)
Hybrid search (vector + keyword)
✅ Output A small set of relevant chunks, not documents.
3️⃣ Augmentation Phase (A)
This is the bridge between search and generation.
Step 1: Combine retrieved chunks
Relevant Chunks → Context
Chunks are:
Deduplicated
Ordered
Truncated to token limits
✅ Typical structure
Context:
[Chunk 1]
[Chunk 2]
[Chunk 3]
Step 2: Augment the user query
Prompt = System Instructions
+ User Query
+ Retrieved Context
Example:
You are an HR policy assistant.
Answer ONLY using the context below.
Context:
<retrieved chunks>
Question:
How does leave approval work?
✅ Why this is powerful
LLM is forced to ground answers
No reliance on model’s internal memory
Enables citations & traceability
4️⃣ Generation Phase (G)
This is where the LLM produces the final answer.
Step 1: Feed augmented prompt to LLM
Prompt → Azure OpenAI GPT Model
Model sees:
The question
The retrieved enterprise knowledge
It does reasoning + language generation
Step 2: Generate response
LLM → Final Answer
✅ Characteristics of RAG responses
Grounded in provided data
Up‑to‑date (depends on index)
Enterprise‑safe
Explainable (can show source chunks)
🔁 Why RAG is superior to fine‑tuning for enterprise data
Aspect
Fine‑tuning
RAG
Data freshness
Static
Real‑time
Cost
High
Low
Hallucination risk
Medium
Low
Source citations
Hard
Easy
Compliance
Risky
Strong
🧠 Key architectural best practices
Chunk size matters more than model choice
Use hybrid search (vector + keyword) in production
Add metadata filtering for access control
Keep prompt instructions strict
Log retrieved chunks for observability
✅ Final mental model
Think of RAG as:
“Search engine + LLM reasoning layer”
Vector DB = semantic memory
Embeddings = meaning encoder
LLM = language + reasoning engine
Why RAG exists
Problem
RAG Solution
LLM hallucinations
Ground answers in real data
Stale knowledge
Fetch live or frequently updated content
Private data
Keep proprietary data outside model training
Cost of fine-tuning
Avoid retraining models
Production Use Cases Commonly Implemented with RAG
Below are real, production-grade RAG use cases that teams deploy—not demos.
1. Enterprise Knowledge Assistant
Use case
Internal chatbot for policies, SOPs, wikis, Confluence, PDFs
How RAG helps
Retrieves policy clauses or documents
Answers with citations and source links
Production details
Chunking by semantic sections
Role-based access filtering at retrieval time
Caching frequent queries
2. Customer Support & Helpdesk Automation
Use case
Support bot answering FAQs, troubleshooting guides, and manuals
How RAG helps
Grounds answers in official docs
Reduces hallucinated instructions
Enhancements
Confidence thresholds → fallback to human agent
Query rewriting for vague user questions
3. Code & Developer Assistants
Use case
Query internal repositories, APIs, and design docs
How RAG helps
Retrieves relevant code snippets
Explains logic using actual implementation
Key technique
Repository-aware chunking (functions, classes)
Metadata filters (language, repo, branch)
4. Legal / Compliance Search
Use case
Contract analysis, regulation Q&A, audit prep
Why RAG is critical
Exact wording matters
Answers must be traceable
Production safeguards
Source citation mandatory
Retrieval-only mode for sensitive answers
5. Analytics & BI Natural Language Interface
Use case
Ask questions over dashboards, metrics definitions, and data catalogs
RAG role
Retrieves metric definitions before generating explanations
Prevents semantic drift (“revenue” vs “net revenue”)
6. Healthcare / Scientific Literature Assistants
Use case
Search clinical guidelines, research papers (for example, Care plans for people who require care from care staff so that the person needing care and the staff can ask questions about how to cope or manage certain situations)
It grounds LLM outputs in trusted, up-to-date data
It’s the default architecture for enterprise LLM applications
Most real-world LLM products today are RAG-based
Re-ranking is a second-pass ranking that improves the quality of retrieved documents. Initial retrieval is fast but approximate. Re-ranking is slower but more accurate. You use both together: retrieve top 100 quickly with vectors, re-rank top 100 accurately with a stronger model.
Artificial Intelligence is a broad field, but most of its modern breakthroughs stem from Machine Learning (ML) and its subfield Deep Learning (DL).
Machine Learning focuses on algorithms that learn patterns from data and improve with experience.
Deep Learning is a specialized subset of ML that uses neural networks with many layers to process large, complex data like images, speech, and text.
2. Concepts & Explanations
Machine Learning Paradigms
Machine Learning (ML) is a core subfield of Artificial Intelligence that enables systems to learn from data and improve over time without being explicitly programmed for every task. In ML, models identify patterns and make decisions based on training data.
Machine learning is the scientific study of algorithms and statistical models that computer systems use to effectively perform a specific task without using explicit instructions, relying on patterns and inference instead.
Building a model by learning the patterns of historical data with some relationship between data to make a data-driven prediction
General Architecture of Machine Learning:
Business understanding: Understand the given use case, and also, it’s good to know more about the domain for which the use cases are built.
Data Acquisition and Understanding: Data gathering from different sources and understanding the data. Cleaning the data, handling the missing data if any, data wrangling, and EDA( Exploratory data analysis).
Modeling: Feature Engineering – scaling the data, feature selection – not all features are important. We use the backward elimination method, correlation factors, PCA and domain knowledge to select the features. Model Training based on trial and error method or by experience, we select the algorithm and train with the selected features. Model evaluation Accuracy of the model , confusion matrix and cross-validation. If accuracy is not high, to achieve higher accuracy, we tune the model…either by changing the algorithm used or by feature selection or by gathering more data, etc. Deployment – Once the model has good accuracy, we deploy the model either in the cloud or Rasberry Pi or any other place. Once we deploy, we monitor the performance of the model. if its good…we go live with the model or reiterate the all process until our model performance is good. It’s not done yet!!! What if, after a few days, our model performs badly because of new data. In that case, we do all the process again by collecting new data and redeploy the model.
ML can be classified into 3 main paradigms:
Supervised Learning : Here the machine learns from labeled data.
Learn from labeled data (input + output).
Example: Predicting house prices from square footage.
Algorithms: Linear regression, decision trees, support vector machines.
In supervised learning, the model is trained on a labeled dataset — where each input is paired with the correct output. The goal is to learn a mapping from inputs to outputs, enabling the model to make accurate predictions on new, unseen data.
Supervised learning is classified into two categories of algorithms: Classification: A classification problem is when the output variable is a category, such as “Red” or “blue”, “disease” or “no disease”. Regression: A regression problem is when the output variable is a real value, such as “dollars” or “weight”.
Examples:
Predicting house prices (input: size, location; output: price)
In unsupervised learning, the model is given input data without labels. The goal is to find hidden patterns, groupings, or structures within the data.
An unsupervised model, in contrast, provides unlabelled data that the algorithm tries to make sense of by extracting features, co-occurrence and underlying patterns on its own.
Examples:
Clustering users based on browsing behavior
Dimensionality reduction for data visualization
Anomaly detection in network traffic
Common Algorithms:
K-Means Clustering
Hierarchical Clustering
Principal Component Analysis (PCA)
Autoencoders
Use Cases:
Market segmentation
Recommender systems
Data compression
Reinforcement Learning (RL)
An agent learns by interacting with an environment, receiving rewards or penalties.
Example: Training a robot to walk, or AI to play chess.
Reinforcement Learning (RL) is a goal-directed learning paradigm in which an agent learns to make decisions by interacting with an environment. It receives feedback in the form of rewards or penalties based on its actions and aims to maximize cumulative reward over time.
Reinforcement learning is less supervised and depends on the learning agent in determining the output solutions by arriving at different possible ways to achieve the best possible solution.
Examples:
Teaching a robot to walk,
Training an AI to play chess or Go
Optimizing delivery routes
Key Concepts:
Agent: The learner or decision-maker
Environment: Everything the agent interacts with
Reward Signal: Feedback for good or bad behavior
Policy: The strategy the agent uses to make decisions
Use Cases:
Game AI
Robotics control
Dynamic pricing
Personalized recommendations
💡 Analogy:
Supervised → A teacher provides answers to all practice problems.
Unsupervised → A student tries to find patterns in problems without answers.
Semi-supervised → Some answers are given, the rest must be figured out.
Reinforcement → Learning by trial and error, like a baby learning to walk.
Traditional ML vs. Deep Learning
Traditional ML
Relies on hand-crafted features (e.g., edge detectors in images).
Works well for small-to-medium datasets.
Examples: Decision Trees, Random Forests, SVMs.
Deep Learning
Learn features automatically from raw data using neural networks.
Requires large datasets and high computational power.
Excels in complex tasks (e.g., speech recognition, image generation).
📘 Diagram (text description):
Traditional ML pipeline: Raw Data → Feature Engineering → Model Training → Prediction.
Deep Learning pipeline: Raw Data → Neural Network (learns features + model) → Prediction.
2.3 Neural Networks: Architecture & Learning
A neural network is inspired by the human brain:
Neurons → simple units that take input, apply a function, and pass output.
Layers →
Input layer (data features).
Hidden layers (transformations).
Output layer (prediction/classification).
💡 Analogy: Imagine a bakery:
Input layer → Ingredients.
Hidden layers → Baking process (mixing, heating, decorating).
Output layer → Final cake.
2.4 Core Concepts
Activation Functions: Decide how much signal passes through a neuron.
Examples: Sigmoid, ReLU, Tanh.
Loss Function: Measures how far predictions are from true values.
Example: Mean Squared Error for regression, Cross-Entropy Loss for classification.
Optimizers: Algorithms that adjust model parameters to minimize loss.
Example: Gradient Descent, Adam optimizer.
Backpropagation: The process of propagating errors backward through the network to update weights.
2.5 Evaluation Metrics
Different tasks require different evaluation metrics:
➡️ This shows how supervised learning can classify emails as spam or not spam.
6. Summary
We explored practical examples: iris classification, digit recognition, and spam detection. Machine Learning enables computers to learn patterns from data.
Main paradigms: supervised, unsupervised, semi-supervised, reinforcement learning. Traditional ML relies on feature engineering; Deep Learning learns features automatically. Key concepts: activation functions, loss functions, optimizers, and backpropagation. Evaluation metrics help measure model performance. Ethical challenges (bias, fairness) must be addressed.
➡️ (Above content is taken by my best selling book Generative AI & Machine Learning)
Conclusion: In a FastAPI project, you can implement several software design patterns to improve modularity, scalability, and maintainability. Here’s a categorized overview of the most relevant patterns and how they apply to FastAPI
As artificial intelligence continues to evolve, it’s essential to distinguish between three foundational yet distinct paradigms: Generative AI, AI Agents, and Agentic AI. While these concepts are closely related, each represents a different level of autonomy, complexity, and capability. This guide breaks down their core differences, practical applications, and how they build upon one another.
1. Generative AI: Creating Content on Demand
What It Is
Generative AI refers to models—like large language models (LLMs) and image generators—that produce original content based on patterns learned from massive datasets. These models are trained on diverse data (text, images, audio, video) and contain billions of parameters.
How It Works
Generative AI is reactive: it responds to user prompts without initiating actions or managing tasks. For example, when prompted to “write a poem about data science,” the model generates a poem but doesn’t decide to write one on its own.
Key Features
Trained on large, multimodal datasets
Generates text, images, audio, or video
Requires prompt engineering to guide output
Examples: OpenAI’s GPT-4, Meta’s LLaMA 3
Supported by tools like LangChain, LlamaIndex, and Grok
2. AI Agents: Task-Oriented Intelligence
What They Are
AI agents extend generative AI by adding autonomy and interactivity. They can perform specific tasks by integrating with external tools and APIs, making them more dynamic and useful in real-world applications.
Why They Matter
LLMs alone can’t access real-time or private data. AI agents solve this by making tool calls—requests to external systems—to fetch current or specialized information.
Example Workflow
User asks a question.
Agent checks if the LLM can answer.
If not, it calls an external API (e.g., for today’s news).
It processes the response.
It delivers a final answer to the user.
Key Features
Built on LLMs with external tool integration
Can retrieve real-time or private data
Perform single, well-defined tasks
Still reactive, but with enhanced capabilities
Act autonomously within defined boundaries
3. Agentic AI: Orchestrating Complex Workflows
What It Is
Agentic AI represents the next level—multi-agent systems that collaborate to complete complex, multi-step workflows. Each agent specializes in a subtask, and together they operate like a coordinated team.
Use Case: YouTube to Blog
An agentic AI system might:
Extract a transcript from a YouTube video
Generate a blog title
Write a summary and description
Compose a conclusion
Each step is handled by a different agent, and outputs are passed between them to produce a polished blog post.
Key Features
Multiple agents working in sequence or parallel
Each agent handles a specific subtask
Enables end-to-end automation of complex workflows
Supports human feedback for refinement
Adds adaptability and robustness through collaboration
4. Comparative Summary
Minimize image
Edit image
Delete image
5. Strategic Implications
Generative AI
Ideal for creative content generation, but limited by its reactive nature. Success depends heavily on prompt quality.
AI Agents
Bridge the gap between static models and dynamic applications. Useful in domains like customer service, analytics, and decision support.
Agentic AI
Best suited for automating complex, multi-step processes. Aligns with real-world workflows and supports scalability, adaptability, and human oversight.
Conclusion
Understanding the distinctions between generative AI, AI agents, and agentic AI is essential for anyone working with modern AI systems. From content creation to autonomous task execution and workflow orchestration, these paradigms represent a clear evolution in capability and complexity. By choosing the right approach, organizations can unlock new levels of efficiency, creativity, and intelligence in their AI-driven solutions.









Recent Comments